














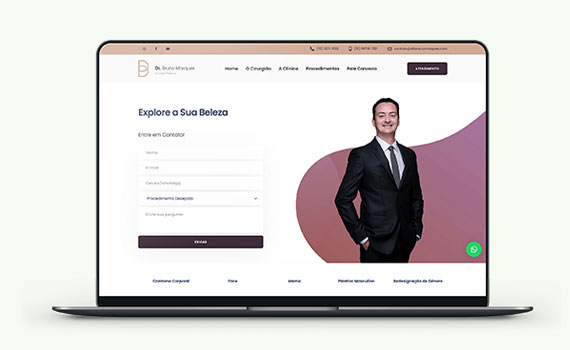
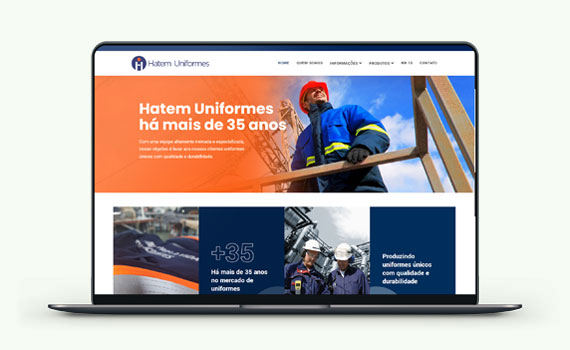
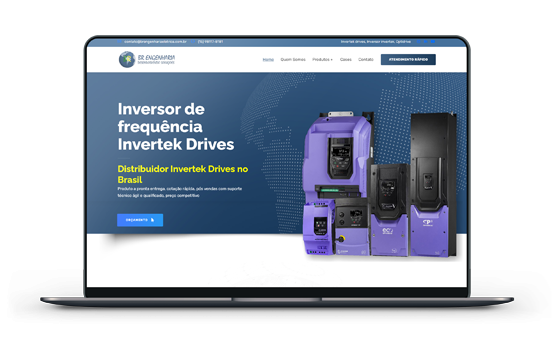


Criação de sites profissionais
Procurando estratégias para a sua empresa ser encontrada no Google em tempos tão competitivos?
Há muitos anos a criação de sites profissionais para empresas tornou-se uma ferramenta indispensável para todo tipo ou segmento de negócios sejam pequenas, médias e grandes corporações.
Logo, a criação de site profissional é a melhor forma da sua empresa ser encontrada no Google, seja com SEO Local ou com uma estratégia de SEO nacional para potencializar seus resultados, receber mais contatos e orçamentos e consequentemente realizar mais vendas.
Se você ainda tem dúvidas, tente encontrar uma grande empresa que não tem um site, muito provavelmente você não irá encontrar.
Ao longo desse texto vamos pontuar os benefícios e provar para você porque a criação de site profissional e a otimização de sites são essenciais para todas as empresas.
Não investir na criação de sites profissionais é um erro?
Sim! Atualmente 84% dos consumidores sentem que as empresas que possuem um site passam mais credibilidade do que as empresas que não tem website.
Sem falar que o acesso à internet vem ganhando cada vez mais espaço na vida das pessoas, segundo dados do IBGE: atualmente o Brasil tem mais de 1 smartphone por habitante, sendo mais de 242 milhões de smartphones em uso no país e com a transformação digital que aconteceu durante a pandemia de 2020, o aumento de vendas online cresceu 75% nesse período.
Além de que, a ausência do serviço de criação de sites profissionais para a empresa ou startup é um grave erro na estratégia de marketing digital, afinal:
- Impacta diretamente no fechamento de novos negócios
- Enfraquece a marca e passa falta de credibilidade
- Dificulta que as pessoas encontrem sua empresa no maior buscador do mundo, o Google
- Não compete com seus principais concorrentes nas buscas regionais ou nacionais.
- Criar um site é essencial por dois grandes motivos:
- Seus possíveis clientes – através de mostrar credibilidade e confiança com seu público e apresentar suas soluções, produtos, serviços e diferenciais competitivos.
- Buscadores – As razões para aparecer no Google são inúmeras, a principal é que você pode receber orçamentos, cotações e venda direta pelo seu site, todos os dias!
Sim, você precisa fazer um site e hora de fazer isso é agora com uma agência web que fala a sua língua e traz total profissionalismo em como criar um site profissional.
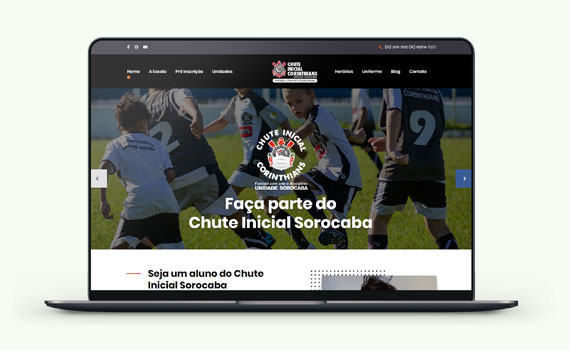
Confira um case de criação de site | Chute Inicial ☆☆☆☆☆

Inúmeras empresas investiram assertivamente na criação de sites profissionais gerenciáveis e conseguiram ótimos resultados, pois uma das funções do site é ser uma ferramenta de negócios e facilitar a experiência do usuário (UX) com diversas aplicações e conteúdo relevante de fácil acesso.
Além de estarem na primeira página e na primeira posição no Google, como é o caso da Escola de Futebol do Corinthians, o Chute Inicial Sorocaba.
Confira esse case pelas palavras do diretor da empresa, Jeison Briculi:
“A parceria com a Agência Webby, já dura desde 2013, o nosso site é muito bacana e bem feito, seguiram todas as etapas de como criar um site profissional, todos que acessam elogiam, eu já indiquei a Webby diversas vezes para os nossos clientes.
As alterações e mudanças no site são feitas de forma bem rápida e eficiente, tanto como as sugestões e melhorias. Tudo isso graças a um site profissional que comunica com o público e recebe atualizações constantes.
O que mais tem ajudado nossa empresa é o bom posicionamento no Google no segmento de escolas de futebol aqui na cidade e gradativamente temos o aumento da procura de alunos que chegam através do site, pelo WhatsApp e Formulário de Contato e mais de 80% acabam efetivando a inscrição e todos os dias recebemos contatos de interessados.
Tudo isso além da criação das artes, banners e trabalhos pontuais. É uma parceria que deu muito certo e já dura quase 10 anos.”
Mas você pode se perguntar: eu já investi para fazer site no Google e porque não tenho resultado?
Muitas pessoas nos procuram e se queixam que o site não dá resultado e não aparece nas buscas do Google. Existem muitos motivos para isso ocorrer, que precisam ser analisados caso a caso com atenção por um desenvolvedor de site.
O que acontece, é que muitas vezes o site da empresa está fora dos padrões, e com isso a necessidade de reformular o site antigo e investir na criação de sites profissionais em WordPress é a melhor opção.
Vamos listar alguns dos problemas mais comuns:
- O site está fora dos padrões atuais de layout e não é responsivo
- Possui imagens e elementos pesados
- Textos pouco relevantes e sem SEO
- Ausência de backlinks de qualidade
- Falta de indexação com o Google e integração com as ferramentas de SEO
- Site sem o certificado de segurança SSL
- Aplicações e linguagens de programação desatualizados ou em versões antigas
- Tentar por conta própria fazer site no Google
Criação de sites para empresas que atendem localmente também é um ótimo negócio!
Um site não serve apenas para encontrar clientes em todo o mundo ou receber contatos aleatórios, mas pode ser uma ferramenta essencial para atrair clientes locais e regionais. Mais conhecido como SEO LOCAL.
Muitas pesquisas no Google são de pessoas procurando algo bem perto delas. Principalmente quando os usuários fazem pesquisas no celular e podem estar procurando naquele momento uma empresa que oferece determinados produtos ou serviços próximos a ela, andando na rua ou no trânsito.
Se você ainda não investiu na criação de sites para empresas ou não tem um site otimizado e responsivo para celular com integração ao Google Maps, você pode estar perdendo muitas oportunidades de venda e de receber contatos diretamente pelo site.
Conclusão: todo negócio precisa de criação de sites profissionais!
Seja uma pequena empresa, advogados, profissionais liberais, prestadores de serviços, autônomos, serviços emergenciais, psicólogos, pessoas famosas, escritórios, indústrias, empresas locais, como toldos e coberturas, todo o tipo de segmento precisa estar online 24 horas por dia.
Crie seu site profissional com uma agência web que entende do assunto.

Criação de sites com marketing digital é o que sua empresa precisa para ter mais resultados!
Em tempos tão conectados, todos nós passamos horas na internet para encontrar determinada solução, e o modo mais fácil é “dar um Google” para tudo.
A ausência dessa importante ferramenta, faz com que sua empresa deixe de lucrar diariamente e a longo prazo pode ser um fator totalmente determinante no rumo da empresa em questão de sucesso ou fracasso.
Clique aqui e tire suas dúvidas sobre o passo a passo para o processo de desenvolvimento e construção de site!
Criação de sites profissionais preço
Como já comentamos acima, a criação do site é imprescindível para o marketing da sua empresa e as vantagens em ter um site são inúmeras.
Um dos fatores que freiam o empreendedor na hora de fazer um site para a sua empresa, é pensar no preço. Engana-se quem pensa que o preço para criação de site é exorbitante e está fora da sua realidade.
O investimento na criação de sites é baixo se comparado com o número de benefícios e que o retorno do investimento geralmente é pago em poucos meses.
Portanto, não perca mais tempo e crie seu site profissional!
Vantagens de criar um site para sua empresa
Mas vamos listar apenas algumas das incríveis vantagens em investir na criação de sites profissionais:
- Presença digital – sua empresa causa uma ótima impressão online por meio de conteúdos relevantes, bem posicionada nos mecanismos de busca e integrada a outras mídias e plataformas digitais.
- Impulsionamento das vendas – você tem a liberdade de apresentar de forma clara seus produtos e serviços, mostrando diferenciais, vantagens, benefícios, depoimentos de clientes, ofertas, descontos e muitos outros artifícios seja para vender online ou para receber contatos e orçamentos.
- Autoridade – produzindo conteúdos de qualidade, você se torna referência no seu nicho de atuação.
- Sua empresa não fica refém das redes sociais.
- O preço para criação de sites profissionais é relativamente baixo, se comparado com investimento em outras mídias como, jornal, tv, revista e anúncios patrocinados em geral.
- Sites otimizados trazem um melhor posicionamento no Google em conjunto com as melhores palavras-chave para ter o máximo de conversões de leads.
- Ser encontrado de forma natural e orgânica sem depender de anúncios e tráfego pago.
- Cria vínculos, tira dúvidas, traz atendimento imediato através de WhatsApp ou chat.
- Um site garante seu sucesso a longo prazo.
- Poder de decisão: 81% dos clientes pesquisam produtos e serviços online antes de comprar.
Você pode obter todos esses benefícios sem gastar uma fortuna.
Conclusão: Invista sem medo na criação de sites para empresas
Ainda dá tempo de investir na criação do seu site! Nós da Agência Webby estamos ansiosos para saber mais sobre suas necessidades para criar o melhor site para sua empresa e fazer do seu site a principal porta de entrada para usuários e futuros clientes que estão buscando produtos e serviços no Google.
Solicite seu orçamento e receba uma proposta comercial com as características, prazo e preço para a criação de sites profissionais.
Esse é o melhor investimento que você pode fazer para consolidar sua empresa no mercado digital a médio e longo prazo. Abra as portas da sua empresa para um público mais amplo, há qualquer hora e em qualquer lugar do mundo!